我們可以根據上下文來推斷整個句子的意思,即使我們有時候沒聽清楚中間幾個字。那如何運用這個概念呢?就有所謂的RNN(recurrent neural networks),其中常用的包含LSTM(long short-term memory),我們直接來看範例:
# Hyperparameters
embedding_dim = 64
lstm_dim = 64
dense_dim = 64
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(lstm_dim)),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Set the training parameters
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
在Colab上這一個epoch約跑24秒,而loss和accuracy如下圖: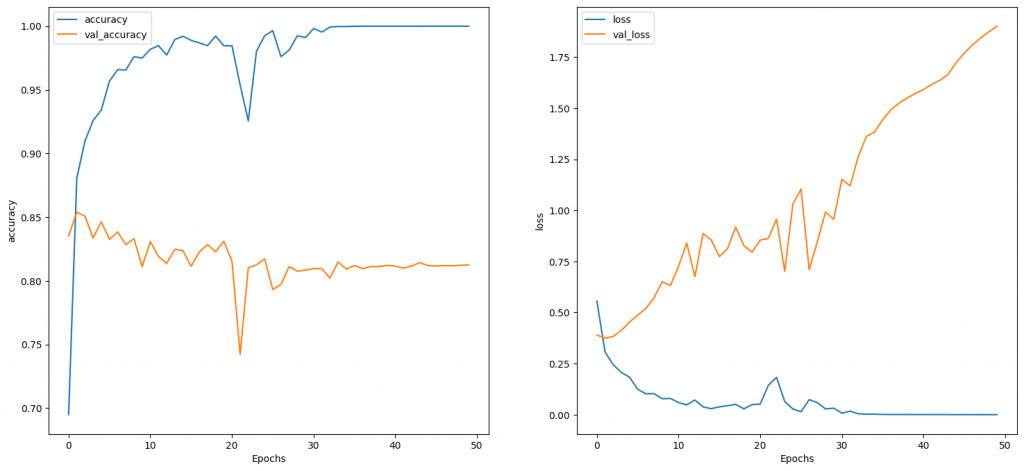
接下來試加了2層的LSTM:
# Hyperparameters
embedding_dim = 64
lstm1_dim = 64
lstm2_dim = 32
dense_dim = 64
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(lstm1_dim, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(lstm2_dim)),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Set the training parameters
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
這一個epoch在Colab上約跑了43秒,在我自己的電腦已經是接近跑不動的等級(可能大於2小時以上,沒跑完過),而loss和accuracy如下圖,在課堂的解說是會比較平滑,但我跑得這次結果差異並不顯著: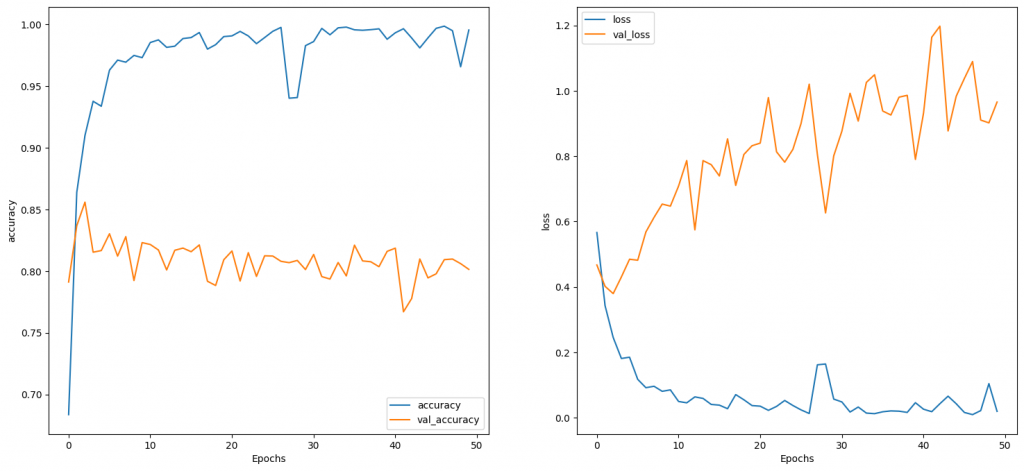
再來試GRU(Gated Recurrent Unit),可以說是簡單版的LSTM:
# Hyperparameters
embedding_dim = 16
gru_dim = 32
dense_dim = 64
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(gru_dim)),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Set the training parameters
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
這一個epoch約跑了16秒,而loss和accuracy如下圖,這就明顯抖動比較大: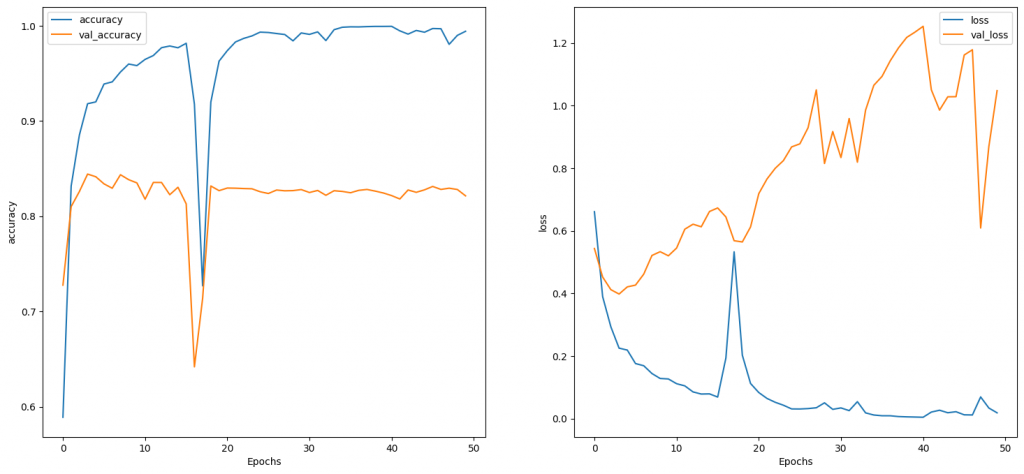
最後是原本的GlobalAveragePooling,我們embedding維度和dense維度和上面設一樣:
# Hyperparameters
embedding_dim = 64
dense_dim = 64
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(dense_dim, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Set the training parameters
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
這一個epoch大約2秒,而loss和accuracy如下圖: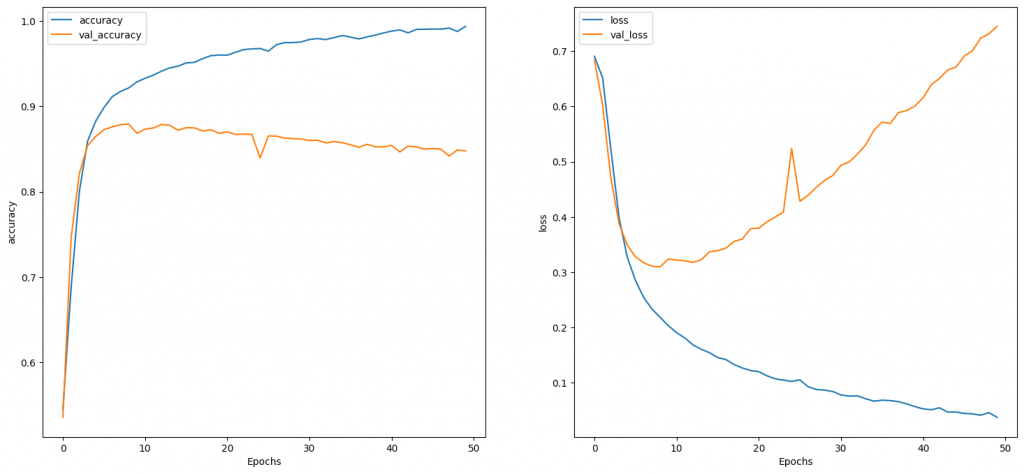
結果都有overfitting的現象,目前除了模擬時間外,沒有哪一個是顯著有感的改變。

